Jeux de caractères HTML
Découvrez les jeux de caractères HTML — ASCII, ANSI, ISO-8859-1 et UTF-8 — et comment déclarer l'encodage avec la balise meta charset.
Un jeu de caractères (ou encodage de caractères) est le mappage qui indique au navigateur comment convertir les octets bruts d'un fichier en lettres, chiffres, ponctuation et symboles affichés à l'écran. Le navigateur doit connaître le jeu de caractères utilisé par une page pour l'afficher correctement.
UTF-8 est l'encodage de caractères par défaut pour HTML5. Il n'en a pas toujours été ainsi. ASCII est apparu en premier, et ISO-8859-1 était le jeu de caractères par défaut de HTML 2.0 à HTML 4.01. Chacun de ces anciens jeux ne pouvait représenter qu'une plage limitée de caractères, ce qui posait des problèmes pour les textes non anglais. Avec l'arrivée d'UTF-8 aux côtés de HTML5 et de XML, la plupart de ces problèmes ont été résolus grâce à une couverture de presque tous les systèmes d'écriture dans un seul encodage.
Cette page présente les principaux jeux de caractères que vous pouvez rencontrer — ASCII, ANSI, ISO-8859-1 et Unicode/UTF-8 — et montre comment déclarer l'encodage dans les pages HTML modernes et legacy.
Ce qui se passe quand l'encodage est absent ou incorrect
Si une page ne déclare pas son encodage, ou en déclare un qui ne correspond pas à la façon dont le fichier a été enregistré, le navigateur devine — et se trompe souvent. Le symptôme le plus courant est le mojibake : du texte illisible où les lettres accentuées, les guillemets typographiques ou les emoji se transforment en chaînes telles que é ou ’.
Au-delà de l'aspect visuellement cassé, un charset non déclaré ou incorrect peut constituer un problème de sécurité : certaines attaques reposent sur le fait que le navigateur interprète des octets selon un encodage différent de celui prévu par l'auteur (par exemple, les attaques de cross-site scripting basées sur UTF-7). Déclarer un seul encodage explicite dès le départ supprime cette ambiguïté. Le choix sûr et moderne est de toujours servir le contenu en UTF-8 et de le déclarer clairement avec <meta charset="UTF-8">.
ASCII
ASCII est le premier standard d'encodage de caractères, également appelé jeu de caractères. Son nom est l'abréviation de American Standard Code for Information Interchange.
Pour chaque caractère stockable, ASCII a défini un numéro unique afin de prendre en charge les lettres majuscules et minuscules (a-z, A-Z), les chiffres de 0 à 9 et un ensemble de caractères spéciaux. Il est basé sur l'alphabet anglais et encode 128 caractères dans un entier binaire de 7 bits. Par exemple, la lettre majuscule A correspond au code 65 (binaire 01000001), a correspond à 97 et le chiffre 0 à 48. Cela fonctionne parce que toutes les informations informatiques sont, en fin de compte, enregistrées sous forme de uns et de zéros binaires dans l'électronique.
Ci-dessous, vous pouvez voir un tableau ASCII faisant correspondre chaque caractère à son code décimal, hexadécimal et binaire.
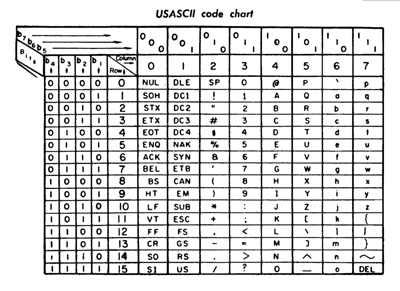
La plus grande limitation d'ASCII est qu'il ne contient pas de lettres non anglaises ni de caractères accentués. Il est encore utilisé aujourd'hui, notamment sur les ordinateurs mainframe, et constitue la fondation sur laquelle les encodages ultérieurs (y compris UTF-8) ont été bâtis.
Cliquez ici pour en savoir plus sur ASCII.
ANSI
ANSI, également connu sous le nom de Windows-1252, était le jeu de caractères par défaut de Windows jusqu'à Windows 95. Il s'agit d'une extension d'ASCII qui ajoute des caractères internationaux. Il prenait en charge 256 caractères en utilisant un octet complet (8 bits).
ANSI était pris en charge par tous les navigateurs depuis son annonce comme jeu de caractères par défaut de Windows.
ISO-8859-1
ISO-8859-1 est devenu l'encodage de caractères par défaut en HTML 2.0, car la plupart des pays utilisent des caractères différents de ceux d'ASCII. Il s'agit également d'une extension d'ASCII, tout comme ANSI, et il ajoute des caractères internationaux. ISO-8859-1 utilise aussi un octet complet pour représenter deux fois plus de caractères qu'ASCII.
Cliquez ici pour en savoir plus sur ISO-8859-1.
Encodage par défaut en HTML 4
En HTML 4, l'encodage était déclaré avec une balise <meta> http-equiv. Puisqu'ISO-8859-1 était le défaut, voici comment le déclarer explicitement :
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1" />Remplacer le charset en HTML 4
Si une page HTML 4 nécessite un encodage différent du défaut ISO-8859-1 — par exemple ISO-8859-8 pour l'hébreu — il suffit de modifier la valeur charset dans la même balise <meta> :
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-8" />La plupart des processeurs HTML 4 comprenaient également UTF-8, ce qui a ouvert la voie à son adoption comme standard dans HTML5.
La méthode HTML5
HTML5 a remplacé la forme verbose http-equiv par un attribut court et dédié :
<meta charset="UTF-8" />Placez cette balise le plus tôt possible à l'intérieur de l'élément <head> — idéalement comme tout premier enfant — afin que le navigateur lise l'encodage avant d'analyser tout contenu textuel.
Unicode UTF-8
UTF-8 est l'encodage de caractères par défaut — et recommandé — pour HTML5.
Étant donné que les jeux de caractères décrits ci-dessus sont chacun limités à 256 caractères au maximum, le Consortium Unicode a développé le Standard Unicode, un catalogue unique qui attribue un numéro unique (appelé point de code) à presque chaque caractère, signe de ponctuation et symbole utilisé dans le monde — dans des milliers de langues, ainsi que les emoji et les symboles mathématiques. UTF-8 est la méthode la plus populaire pour encoder ces points de code en octets.
Pourquoi UTF-8 est le standard moderne
Trois propriétés font d'UTF-8 le choix naturel pour le web :
- Couverture universelle. Il peut représenter chaque point de code Unicode, de sorte qu'une seule page peut mélanger de l'anglais, de l'arabe, du chinois et des emoji sans changer d'encodage.
- Compatible ASCII. Les 128 premiers points de code sont encodés exactement comme les mêmes octets individuels qu'en ASCII. Tout fichier ASCII ordinaire est déjà un UTF-8 valide, ce qui signifie que des décennies de textes plus anciens et d'outils continuent de fonctionner.
- Efficacité à largeur variable. Les caractères courants n'occupent qu'un seul octet, tandis que les moins courants utilisent deux, trois ou quatre octets seulement selon les besoins. Les documents essentiellement en anglais restent compacts, sans rien laisser de côté.
En HTML, l'attribut charset sur la balise <meta> spécifie l'encodage :
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>UTF-8 example</title>
</head>
<body>
<p>English, Русский, 中文, العربية, 😀</p>
</body>
</html>Gardez <meta charset="UTF-8"> comme première chose dans le <head> (dans les 1024 premiers octets du document). Si elle arrive trop tard, le navigateur peut commencer à analyser le texte avec le mauvais encodage avant de voir la déclaration.
Caractères multi-octets et le BOM
En UTF-8, un seul caractère peut s'étendre sur plusieurs octets. Par exemple, le signe euro € (point de code Unicode U+20AC) est stocké sous la forme des trois octets E2 82 AC, tandis qu'un caractère comme A n'occupe toujours qu'un seul octet. C'est ce que signifie « à largeur variable » en pratique.
Vous pouvez également rencontrer le BOM (Byte Order Mark), une séquence optionnelle et invisible d'octets (EF BB BF pour UTF-8) au tout début d'un fichier qui indique son encodage. Un BOM n'est pas obligatoire pour UTF-8 et il vaut généralement mieux l'omettre en HTML, puisqu'un <meta charset="UTF-8"> explicite fait déjà le travail, et qu'un BOM parasite peut parfois provoquer des problèmes de rendu.
Pour insérer des symboles spécifiques sans vous soucier de la façon dont votre éditeur enregistre le fichier, vous pouvez également utiliser des entités HTML nommées ou numériques (par exemple € pour €).
Tous les processeurs HTML5 prennent en charge UTF-8. Notez que les processeurs XML exigent strictement UTF-8 ou UTF-16.